[R language] : 데이터 다루기 (3)

데이터 다루기
연습데이터 설명
이번에 다룰 데이터는 한 회사의 인사관리 데이터이다.
이 데이터에는 여러가지 변수들이 있다.
- satisfaction_level : 직무 만족도
- last_evaluation : 마지막 평가점수
- number_project : 진행 프로젝트 수
- average_monthly_hours : 월평균 근무시간
- time_spend_company : 근속년수
- work_accident : 사건사고 여부 (0: 없음, 1: 있음, 명목형)
- left : 이직 여부 (0: 잔류, 1: 이직, 명목형)
- promotion_last_5years : 최근 5년간 승진 여부 (0: 승진 x, 1: 승진, 명목형)
- sales : 부서
- salary : 임금 수준
데이터 불러오기 및 Strings 확인
데이터를 불러올 때는 파일이 저장되어있는 경로를 복사한다음 (우클릭 후 copy path 클릭) 파일경로/파일명.csv를 입력해주면 된다.

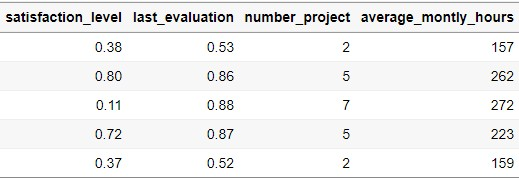
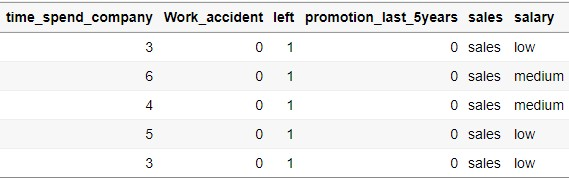
데이터를 불러온 다음에는 당연히 데이터가 제대로 불러와졌는지 확인을 해야된다. 데이터를 확인하는 대표적인 명령어는 head(), str(), summary()가 있다.
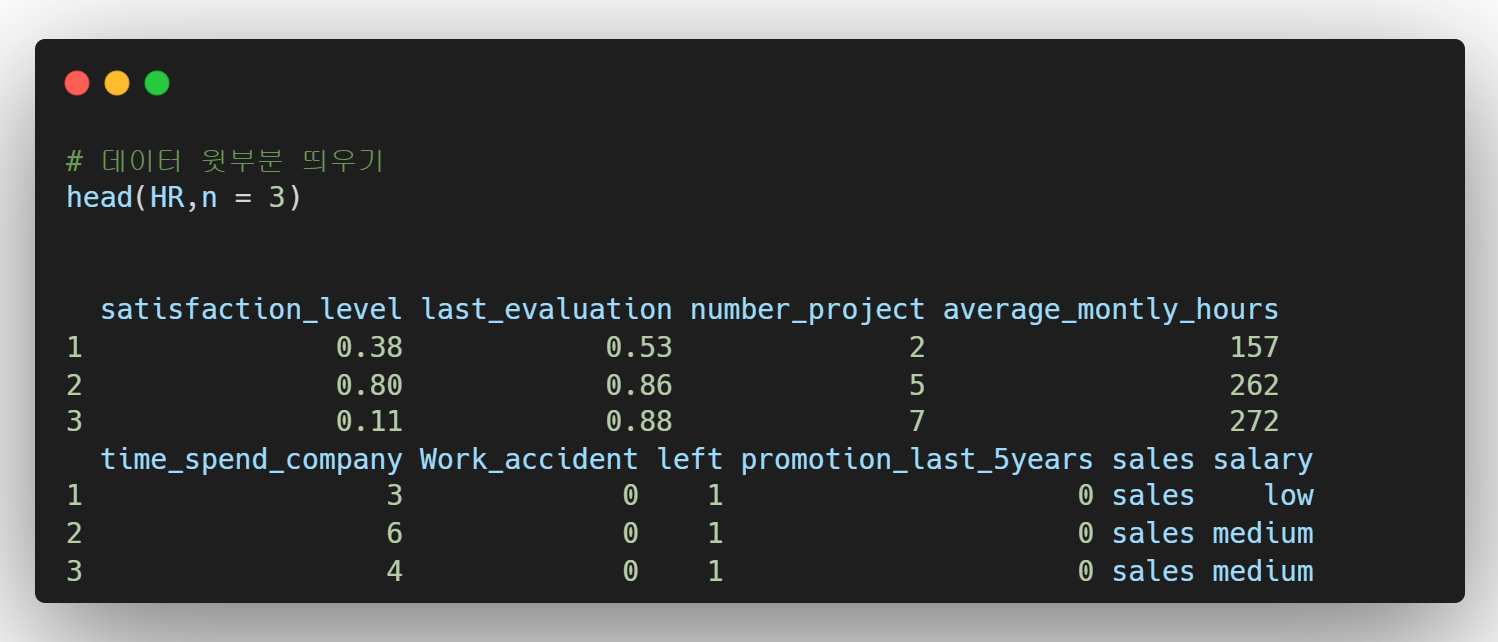
- head() 데이터의 윗부분을 출력하는 명령어
- str(), 데이터의 shape, strings 파악
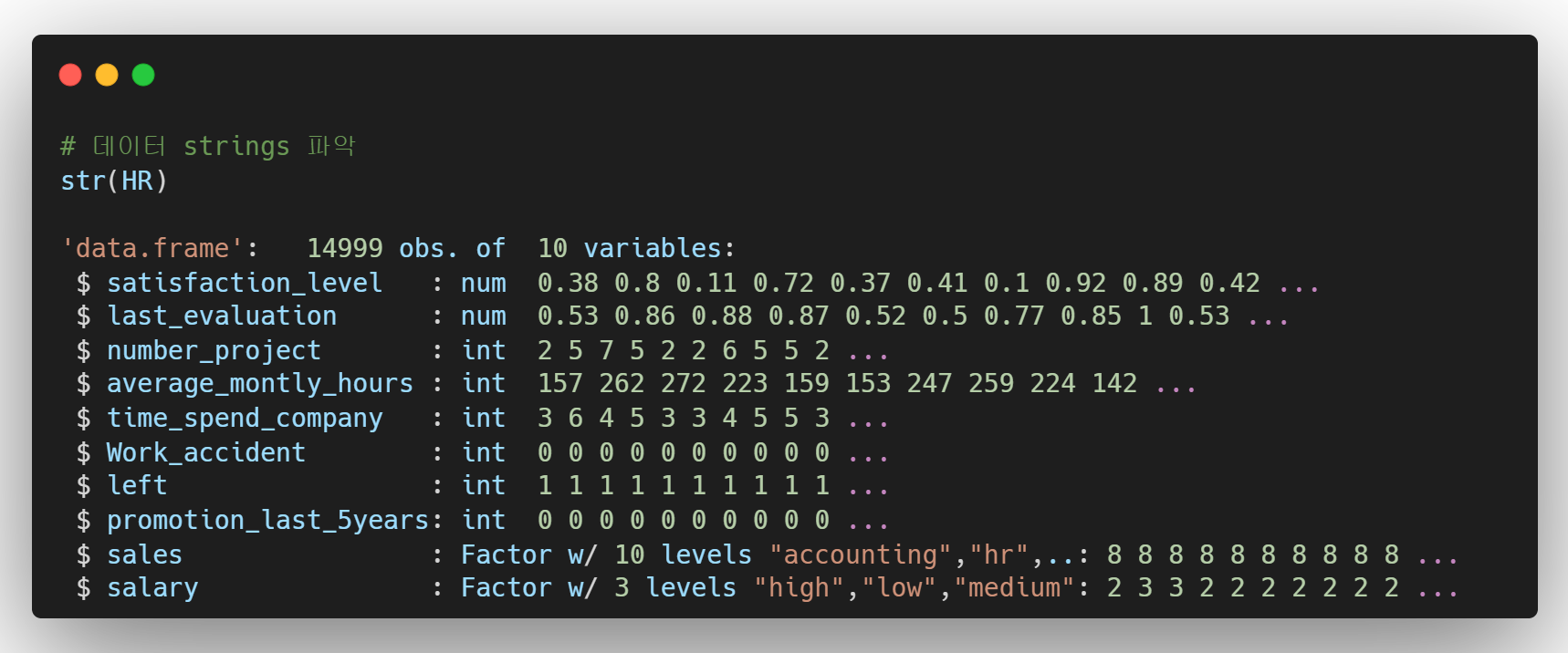
여기서 중요한 것은 각 변수들이 어떤 strings를 가지는지 확인하는 것이다. num, int, Factor등 어떤 변수들이 어떤 strings로 저장되었는지는 R이 해당 변수를 어떻게 인식하고 있는지와 같은 의미이다.
- 데이터 요약해서 보기
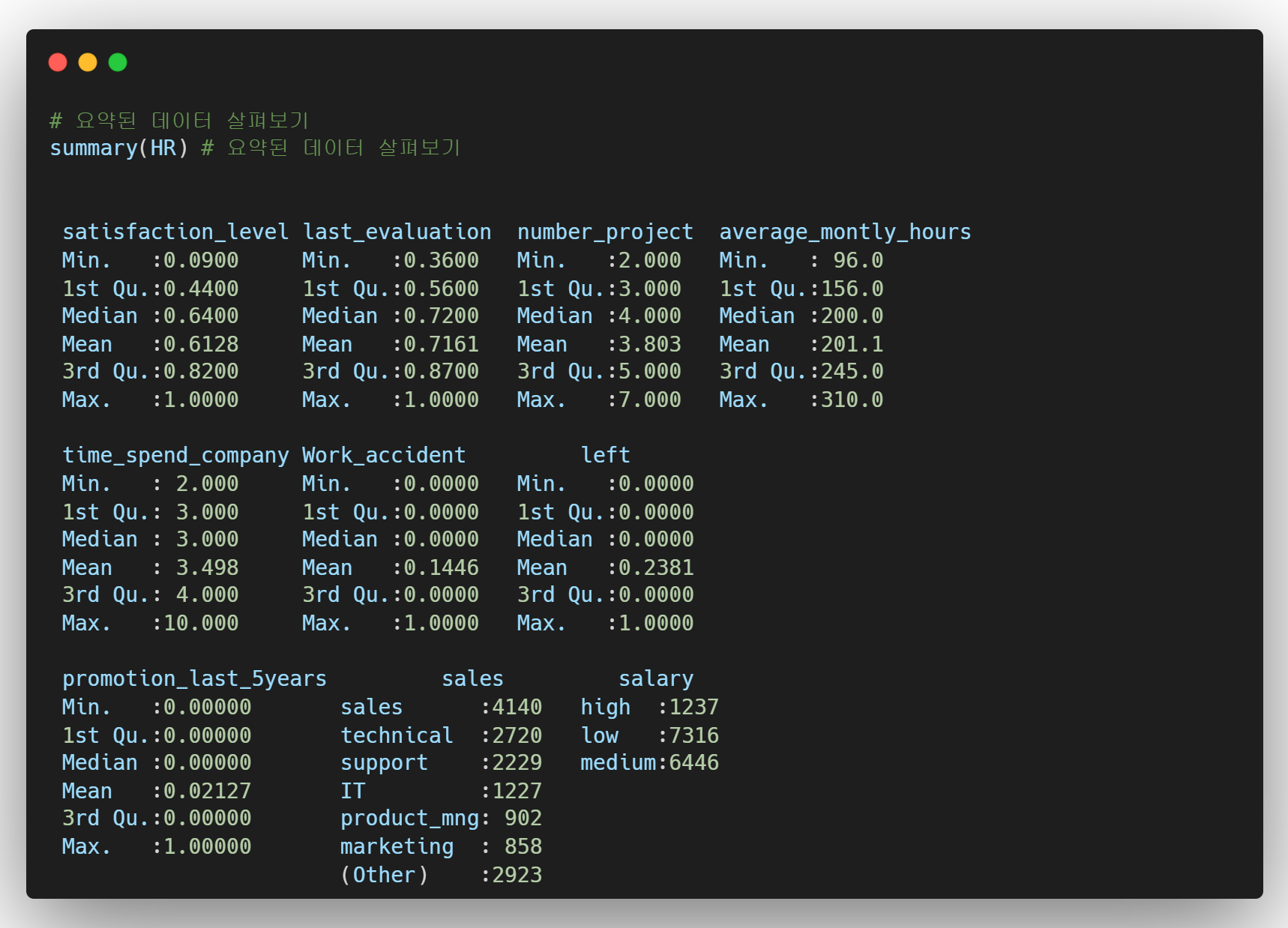
Summary()는 데이터에 포함된 모든 변수들에 대한 요약값을 보여준다. num 및 int는 변수의 최솟값, 최댓값, 평균, 중위수 등을 보여주고 Factor 형태는 개수를 집계내주는 것을 확인할 수 있다.
데이터 strings 변경
Work_accident, left, promotion_last_5years는 명목형 변수라 R에서 Factor 형태로 들어와야 하지만, R에서는 아직 해당 변수들을 int로 인식하고 있다. 이건 원래 데이터의 특성이 아직 R에 반영이 되지 않은 것이기 때문에 strings 변환을 통해 알맞게 변환 해주어야 한다.
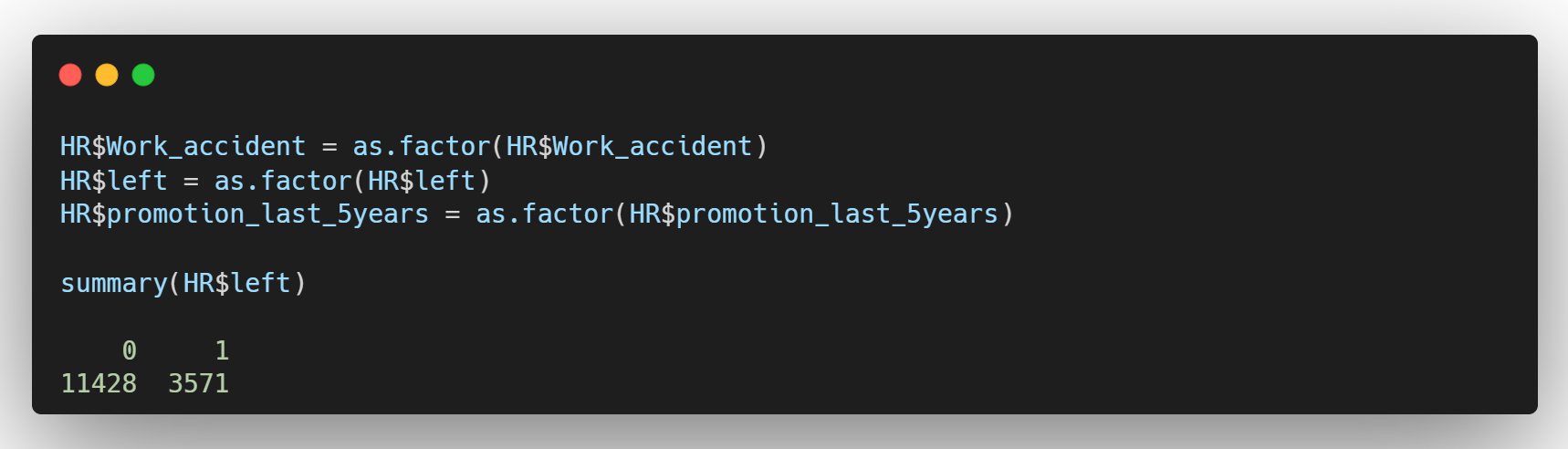
left 변수가 numeric으로 되어 있을 때와 Factor로 되어 있을 때, 요약값이 다르게 표시되는 것을 알 수 있다. 이렇게 분석하고자 하는 변수가 명목형, 순서형, 연속형인지 제대로 파악을 해야한다.
변수의 척도에 대한 확인이 끝난 다음에는 변수의 분포를 직접 확인 해보는 작업이 중요하다. 왜냐하면 분석하고자 하는 변수의 분포를 보고 데이터 핸들링 방향을 설정하게 되기 때문이다. 또한 앞으로 다루게 될 분석에서 쓰이는 선형모형들은 확률변수의 분포를 가정하고 진행하는 경우가 대부분이다. 만약 분석하고자 하는 확률변수의 분포가 가정되어있는 분포와 같지 않다면 변환을 통해 분포를 맞추어 줘야 한다.
조건에 맞는 데이터 가공하기
데이터 핸들링은 분석에서 가장 중요한 부분을 차지하며, 실제 분석에 들이는 시간의 80 ~ 90%는 데이터 핸들링이 차지하는 경우가 많다.
기본적으로 주어진 데이터를 Raw 데이터라고 한다. 하지만 대부분의 경우 Raw 데이터에서 바로 모델링을 진행하는 경우는 없다. Raw 데이터로 분석을 진행하다, 중간에 분석이 틀어졌을 경우 다시 처음부터 시작해야 하는 문제점이 존재하며, 이는 생각보다 매우 큰 시간을 소모하게 된다. 상황에 따라서는 데이터를 조건에 따라 뽑아야 할 때도 있고, 연속형 변수를 이산형 변수로 묶어줘야 할 떄도 존재한다.
조건에 맞는 값 할당하기 ifelse()
ifelse()는 R에서 매우 쓰임이 많은 조건 함수이다. R에서 사용하는 방법은 엑셀에서의 쓰임과 매우 비슷하다.
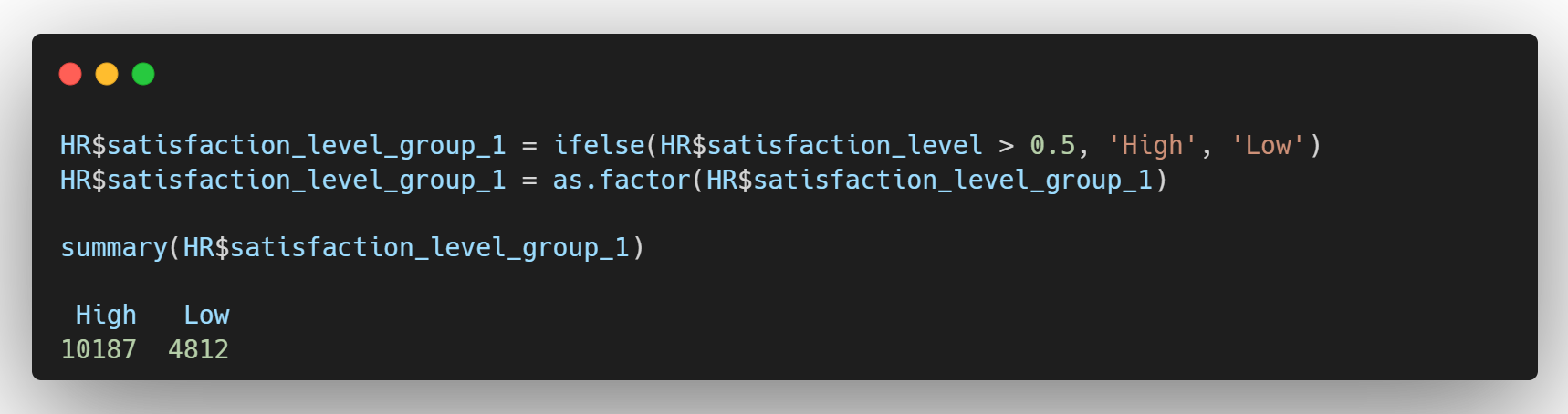
- satisfaction_level이 0.5보다 크면 High 크지 않다면 Low 부여
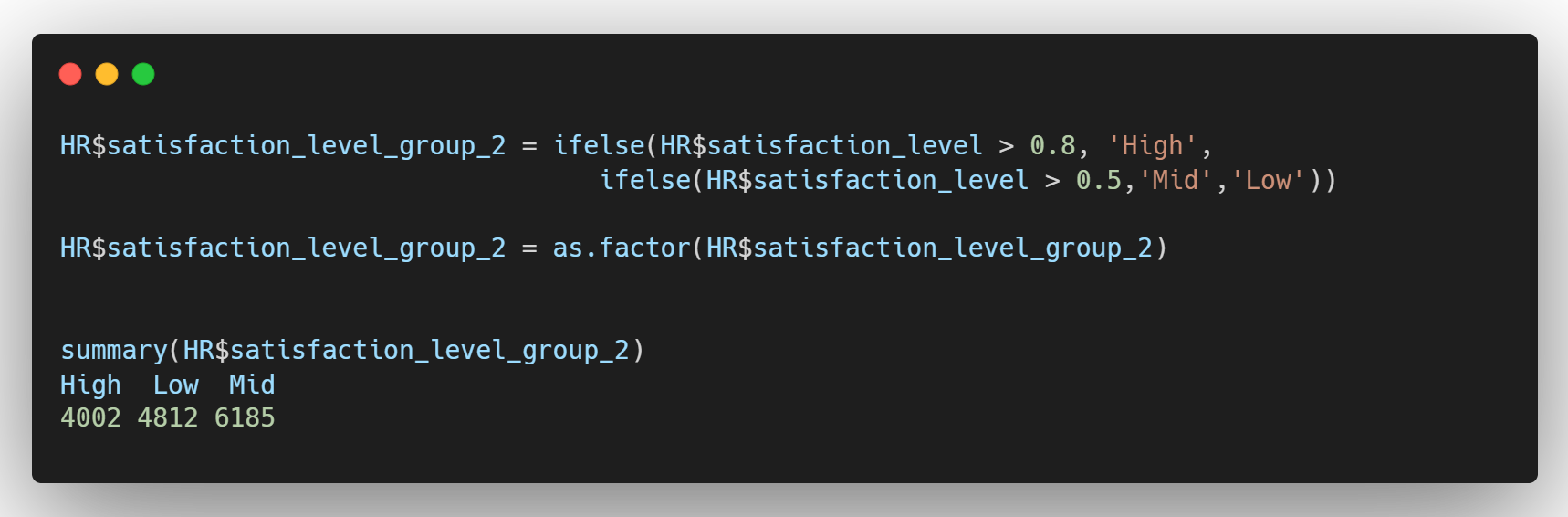
- satisfaction_level이 0.8보다 크다면 High, 0.5 ~ 0.8이면 Mid, 그렇지 않다면 Low
조건이 추가 되었을 경우에는 ifelse(ifelse()) 형태로 중첩해서 사용하면 된다.
조건에 맞는 데이터 추출하기 subset
subset() 함수는 조건에 맞는 데이터를 추출하는 명령어이다.
- salary가 high인 직원들만 추출하여 HR_high이라는 새로운 데이터셋 생성
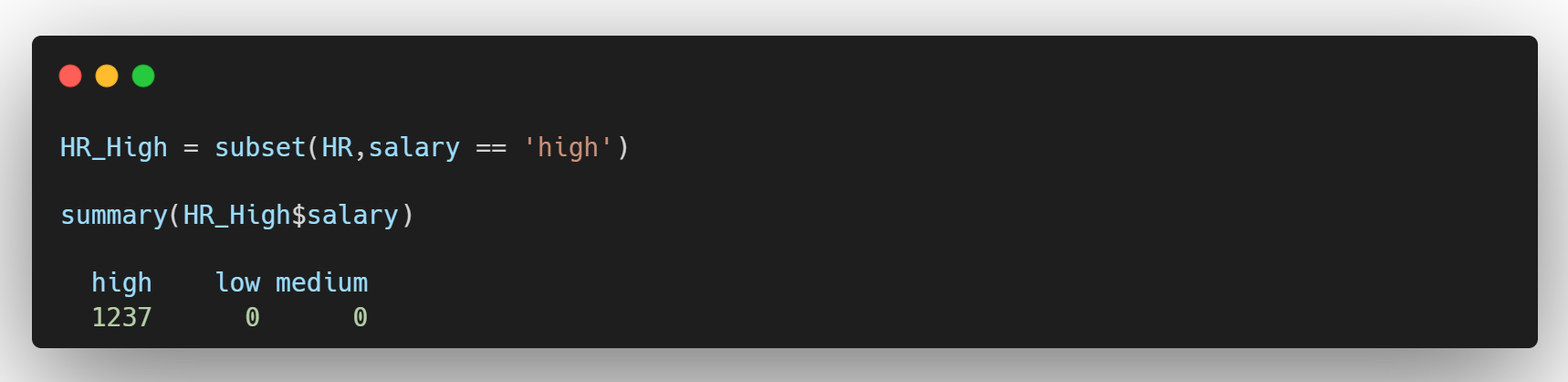
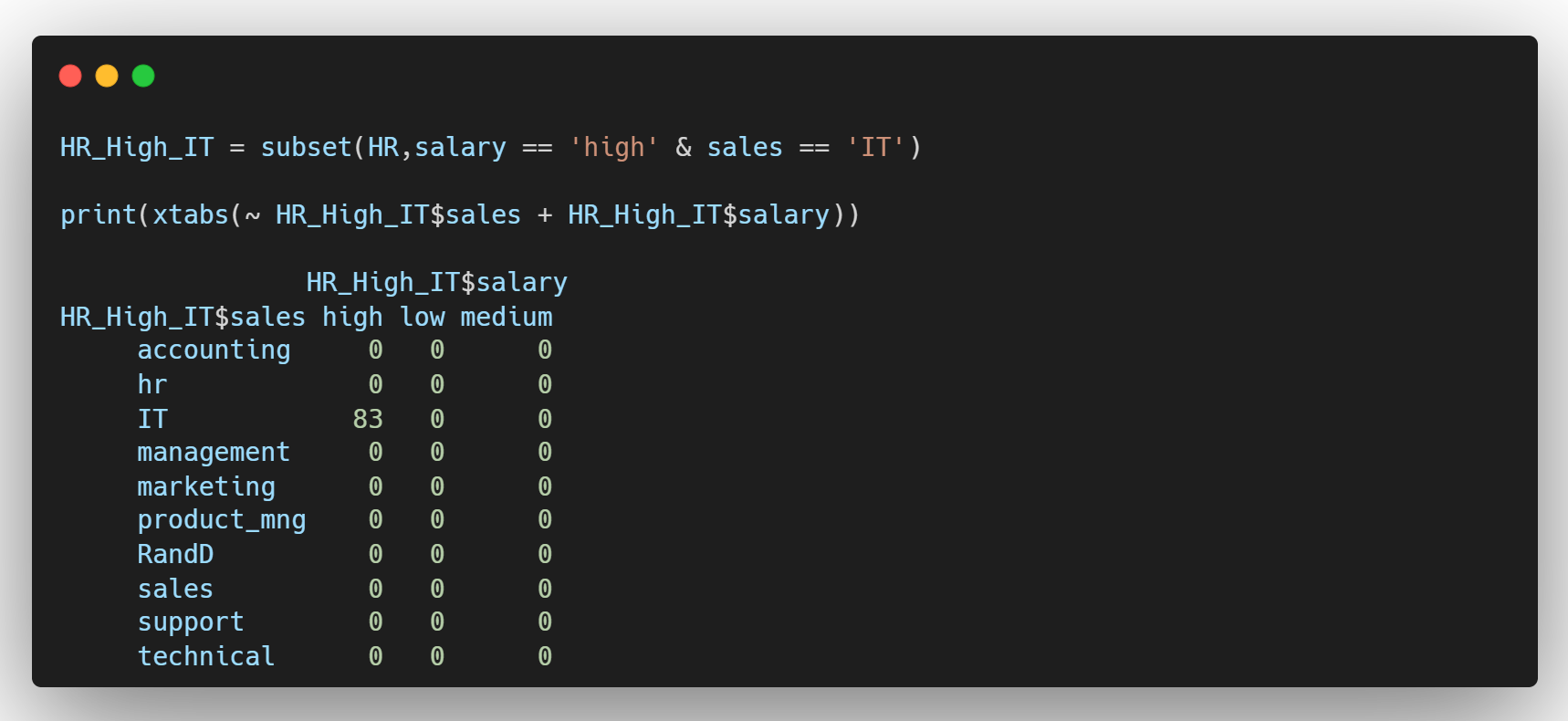
- salary가 high이면서, sales가 IT인 직원들만 추출하여 HR_High_IT 생성
조건에 맞는 집계 데이터 만들기
조건에 따라 새로운 집계된 데이터를 만드는 것은 분석할 때 매우 중요한 기법이다. 엑셀을 사용해봤다면 피벗테이블을 만들어봤을텐데, 비슷한 기능을 plyr 패키지를 통해 만들 수 있다.
데이터를 편하게 집계 내기 위해서는 다음의 패키지가 필요하다.

ddply를 활용한 집계 데이터 만들기
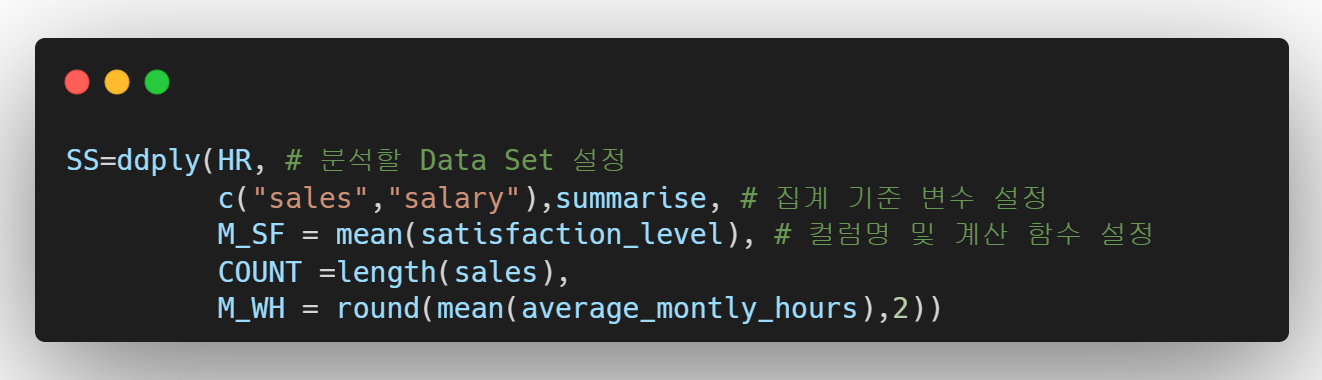
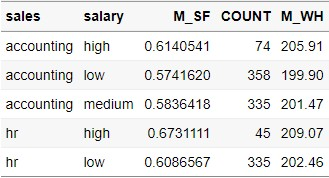
집계 데이터를 만드는 방법은 여러가지가 있지만 가장 기본적인 ddply()함수를 사용해보자.
- 분석할 데이터 설정
- 집계 기준 변수 설정
- 집계 값을 저장할 컬럼명 및 계산 함수 설정
ddply(데이터, 집계기준, summarise, 요약변수)
ggplot2 기본 시각화
ggplot2 패키지는 R, Python에서 그래프를 쉽게 그릴 수 있는 패키지이다. 처음에는 어려울 수 있지만, 그래프를 그리는 방식은 대부분 동일하기 때문에 좀 그리다 보면 원하는 그래프를 자유자재로 그릴 수 있다.
ggplot2 기본 문법구조
ggplot2를 이용해 그래프를 그리는 일은 우리가 직접 그래프를 그리는 과정과 유사하다. 만약 손으로 그래프를 그리게 되면 다음과 같은 과정을 따를 것이다.
- 축을 그린다.
- 그래프를 그린다.
- 범례, 제목, 글씨 등 기타 옵션을 수정한다.
ggplot2 역시 마찬가지라고 생각하면 된다.
- 축을 그린다 -> ggplot(데이터명, aes(x = 변수1, y = 변수2)) (x축 y축 정하기)
- ggplot은 ggplot2의 시작 명령ㅇ어이며, 여기서 그래프를 그릴 데이터와, 변수를 설정해 준다.
- aes는 aesthetic의 약자로, 그래프에 변수를 설정해줄 때는 무조건 aes안에 들어가 있어야 한다.
- 그래프를 그린다.
- geom_bar(), 막대도표 그리기
- geom_histogram(), 히스토그램 그리기
- geom_boxplot(), 박스플롯 그리기
- geom_line(), 선 그래프 그리기
- labs( ) , 범례 제목 수정
- ggtitle( ), 제목 수정
- xlabs( ), ylabs( ), x축 y축 이름 수정
예시로 그래프를 한번 그려보자.


ggplot만 입력을 해보면 plot창에서 회색 바탕면이 생기고, 여기서 aes와 함께 축 설정을 해주면 x축이 생긴다.

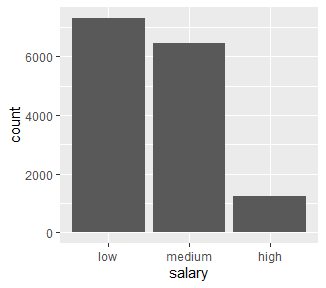

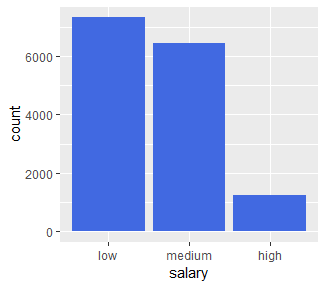
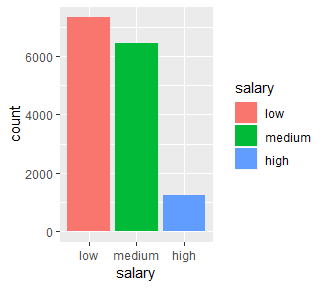
ggplot()으로 만든 바탕색에 + geom_bar()를 해주면 막대표가 만들어지고 fill 함수를 통해 색칠여러가지 색깔로 색칠할 수 있다.
ggplot2는 이렇게 하나씩 그리고 싶은 조건들을 추가해주면서 그리면 편하게 그릴 수 있다.