[R language] : 기초 문법 (5)

이전보다 조금 더 어려운 데이터들로 R을 공부해보자.
데이터 설명
데이터 출처는 Kaggle이다.
변수 설명
- Rank
- Title : 영화 제목
- Genre : 영화 장르
- Description : 영화 설명
- Director : 감독명
- Actors : 배우
- Year : 영화 상영 년도
- Runtime..Minutes : 상영 시간
- Rating : Raging 점수
- Votes : 관객 수
- Revenue..Millions : 수익
- Metascore : 메타 스코어
결측치
결측치는 말 그대로 데이터에 값이 없는 것을 뜻한다. 줄여서 NA라고 표현하기도 하고 Null 이라고도 한다. 결측치는 데이터를 분석하는데에 있어서 매우 방해가 되는 존재이다.
하지만 그런 결측치를 다 제거해버리는 경우, 결측치의 비율에 따라서 막대한 데이터 손실을 불러일으킬 수 있다. 그렇다고 결측치를 잘못 대체할 경우, 데이터에 편향이 생길 수 있다.
결론은 결측치를 정확히 처리하기 위해서는 시간을 많이 투자해야 되고, 무엇보다 데이터에 기반한 결측치 처리가 진행되어야 분석을 정확하게 진행할 수 있다.
R을 통한 결측치 처리
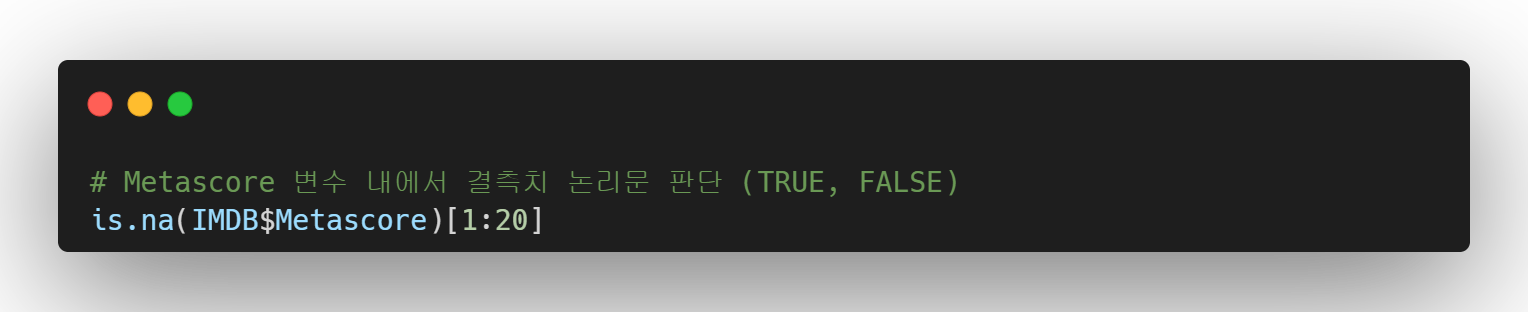
- 결측치 확인



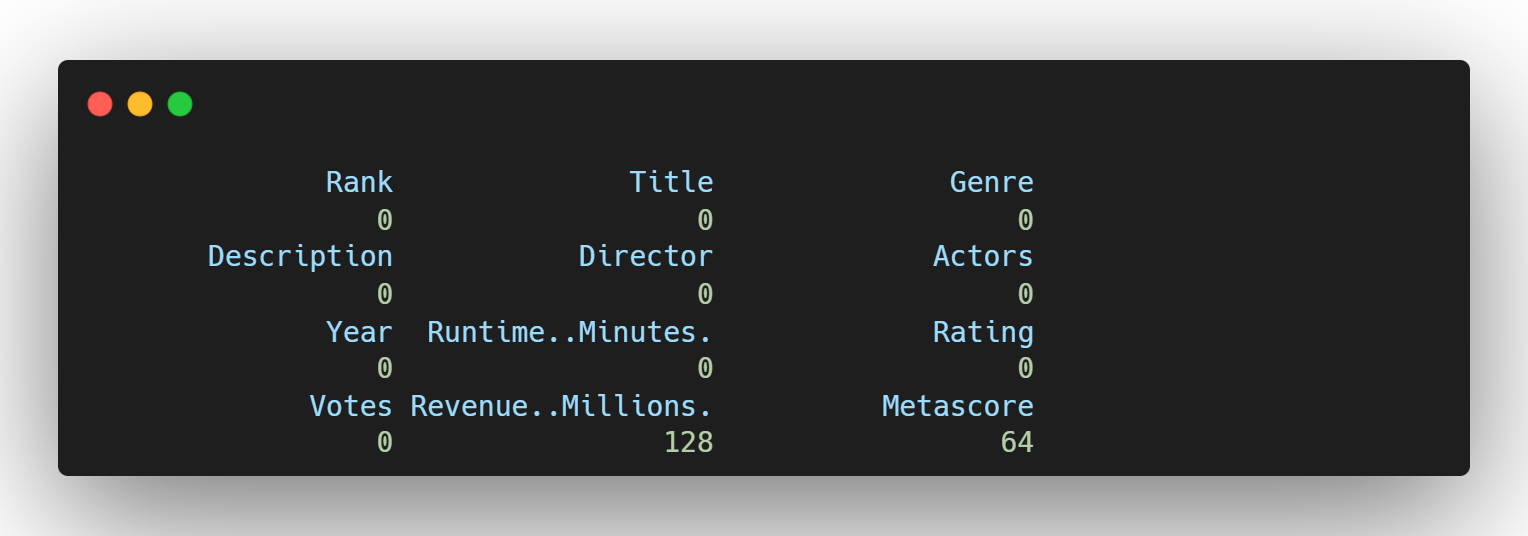
- 결측치 제거
전부 삭제하는 방법은 가장 극단적인 방법이다. (결측치가 하나라도 포함된 행 삭제)


특정 변수에 결측치가 존재하는 행만 삭제하는 경우

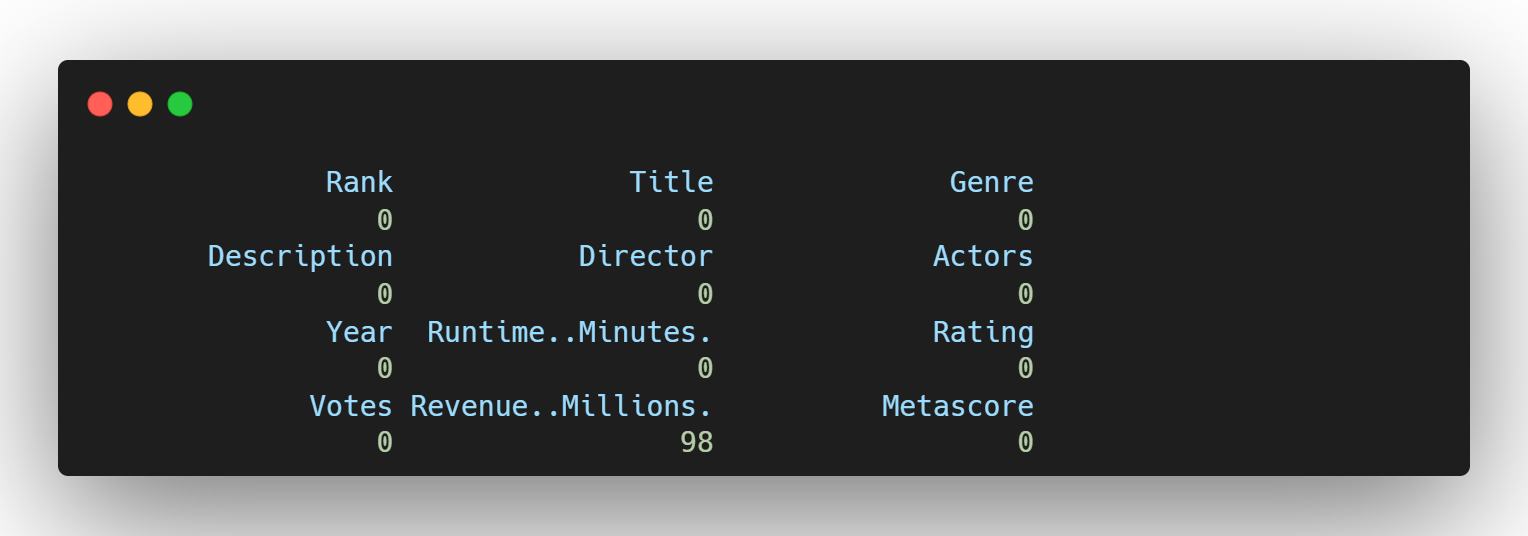
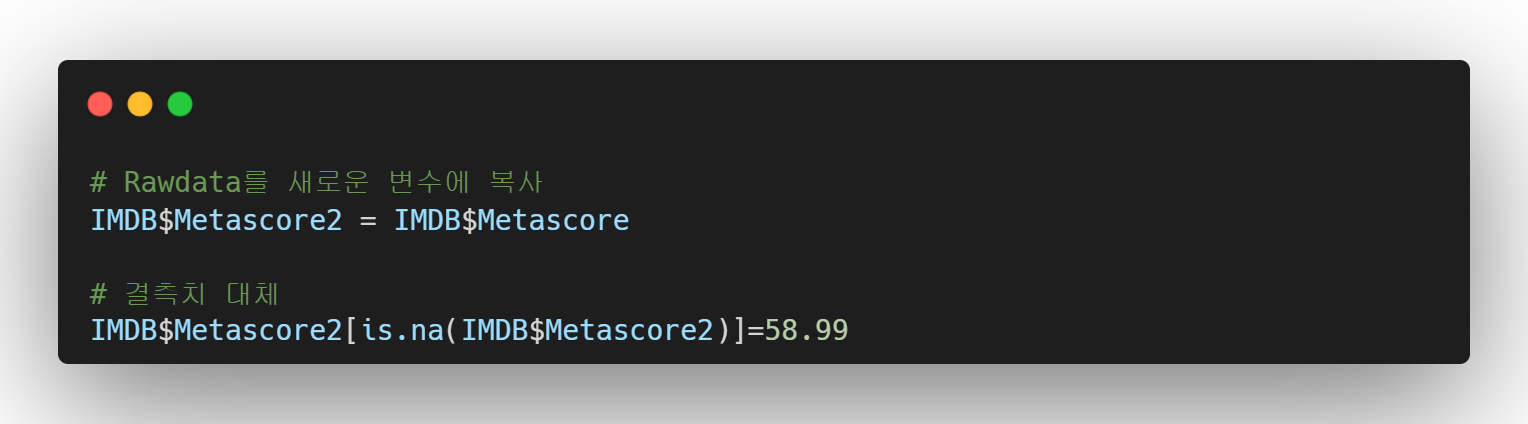
결측치를 특정값으로 대체할 경우
is.na가 True인 값(결측치)들에 대해 58.99로 지정
결측치를 생략하고 계산할 경우

결측치 처리시 주의할 점
데이터를 다룰 때, 기본적으로 raw 데이터는 절대 건드리는 것이 아니다. 보통의 경우, 데이터를 새로 복사를 해두고 진행을 하는 것이 좋은 습관이다. 때로는 나머지 정보를 잃지 않기 위하여 합리적으로 결측치를 대체해야 할 필요가 있다. 가장 기본적인 방법은 다음과 같다.
- 연속형 변수 : 평균으로 대체
- 이산형 변수 : 최빈값으로 대체
하지만 이렇게 무턱대고 결측치를 대체하는 경우 데이터가 심하게 쏠릴 수 있다. 결측치를 대체할 때는 항상 다음의 사항들을 확인해야 한다.
- 결측치의 비율
만약 결측치의 비율이 상당한 경우, 일단 지우고 보는 방식은 크나큰 정보 손실을 불러올 수 있다.
- 데이터의 분포
데이터를 분석 할 때, 항상 데이터의 분포를 확인하고 진행해야된다. 데이터가 평균을 중심으로 균형있게 퍼져있는 정규분포 형태를 띄고 있는 경우라면 모르겠지만, 대부분 데이터는 그렇게 이상적이지 않다.
- 다른 변수와의 관계가 있는지
다른 변수와의 관계를 파악하여 결측치를 대체하는 방법도 있다. 전문적인 용어로는 Missing value Imputation이라고 한다.
결측치 처리를 위한 데이터의 분포 탐색
결측치를 처리하기 위해, Revenue>>Millions의 분포에 대해 확인해 보자.
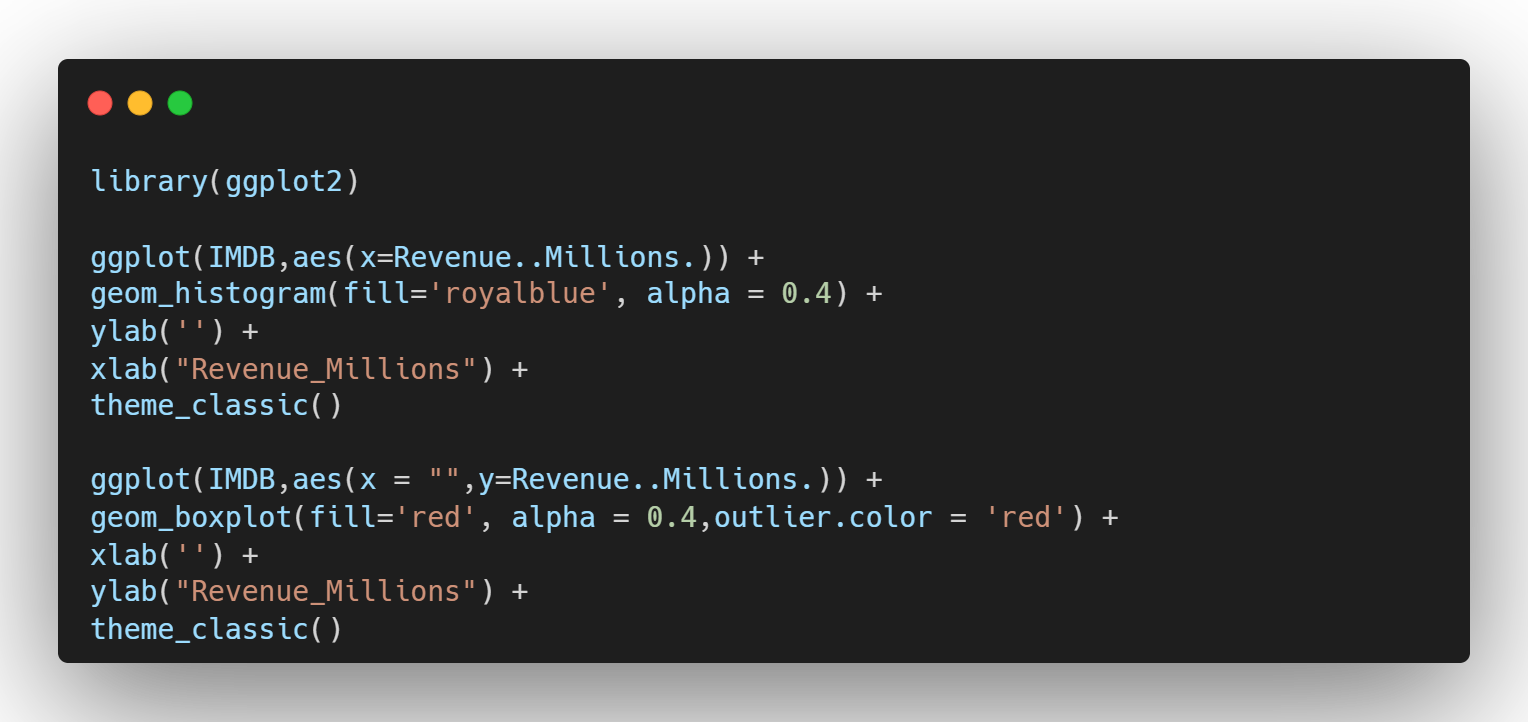
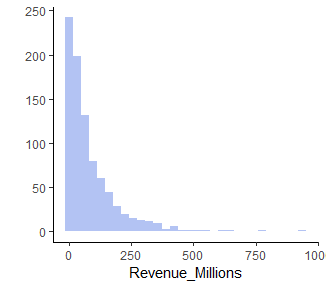
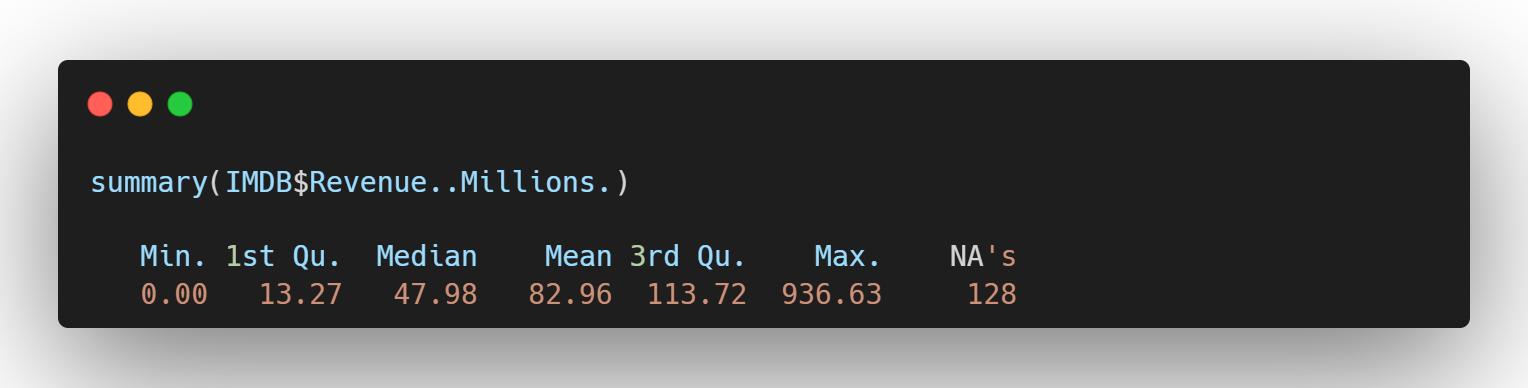
Revenu_Millions를 볼 때 데이터가 한쪽으로 매우 치우쳐져 있다. 이런 분포는 항상 평균과 중위수의 차이를 확인해봐야한다. (평균 82.96 중위수 47.98) 따라서, 이런 분포의 데이터의 결측치는 평균으로 대체하면 평균은 극단값에 영향을 받기 때문에 매우 위험하다. 극단값은 패턴을 벗어난 특수한 상황이지, 결코 일반적인 상황을 대변해주지 않는다.
- 그럼 어떻게 해야하는가?
평균보다는 중위수가 안전하다. 중위수는 극단값에 영향을 받지 않기 때문이다. 물론 중위수로 대체 하는 것은 차선책이지 완벽한 방법은 아니다. 다른 변수들과의 관계를 보면서 대체하는 것은 많은 시간을 요구하지만, 더 정교한 분석결과를 확인할 수 있다.
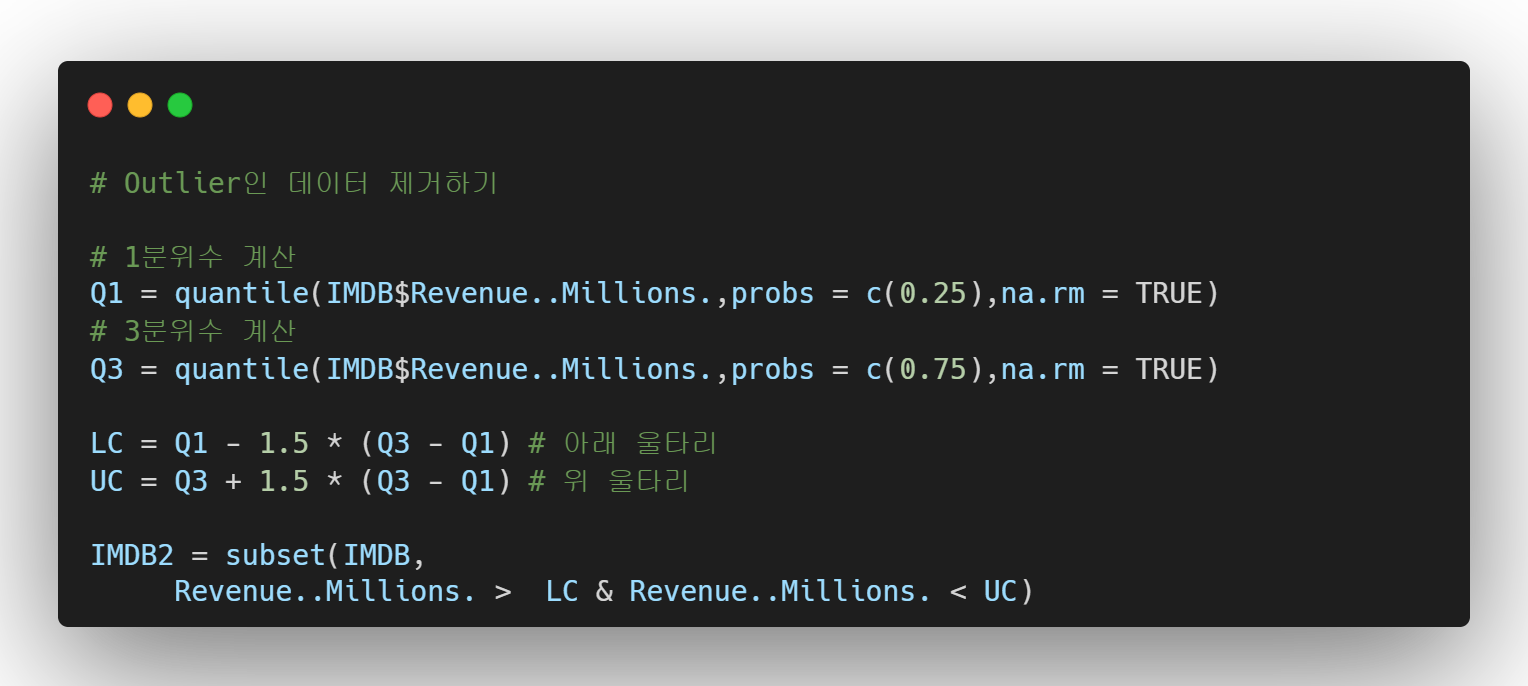
이상치 (outlier) 뽑아내기
이상치는 패턴에서 벗어난 값으로 정의 내릴 수 있다. 또는, 중심에서 좀 많이 떨어져 있는 값이라고 할 수 있다.
이상치는 평균에 막대한 영향을 미친다. 예를 들어 [1, 2, 3, 4, 5]의 평균은 3이지만 [1, 2, 3, 4 ,100]의 평균은 22이다. 하지만 중위수는 3으로 같다. 따라서 종종 평균으로 값을 나타내기 보다는 중위수로 요약값을 나타내는 경우도 있다.
이상치 여부는 다음과 같이 계산한다.
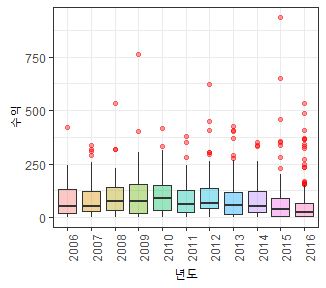
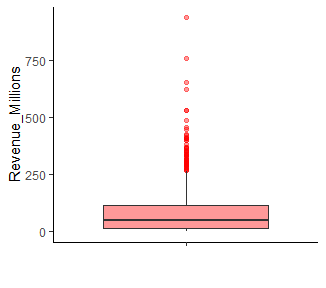
박스플롯을 그린 이유는 이상치 탐색을 가장 하기 좋은 플롯이 박스 플롯이기 때문이다. 좀더 살펴보면
상자 안에 그려져 있는 직선은 중위수를 나타낸다. 상자의 밑변은 1분위수, 윗변은 3분위수이다. 상자 테두리 외부에 직선은 울타리라고 한다.
이 울타리를 벗어난 값을 이상치라고 한다. 이상치는 기본적으로 통계 추정에 있어 방해가 된다. 통계분석은 전부 귀납법인데, 이상치같은 특수 케이스가 규칙을 만드는데 방해 되기 때문이다.
- 이상치 처리방법
제거를 하는 방법이 흔히 쓰이긴 하지만, 결국 데이터를 버리는거니 좋은 방식은 아니다. 데이터 변형을 통해 이상치 문제를 줄여보자.
통계추정에서는 정규 분포를 맞추어 주는 것이 매우 중요하다. 보통 이상치로 인해 한 쪽으로 치우친 분포는 log 변환을 통해 정규성을 맞추어주고는 한다.