[R language] : 문자열 데이터 다루기 (6)

문자열 데이터 다루기
문자열을 다룰 때 기본적으로 숙지해야 될 명령어들이 있다.
- gsub() : 문자열 대체
- strsplit() : 문자열 분리
- paste() : 문자열 합치기
- substr() : 문자열 추출
- Corpus() & tm_map() & tdm() : 텍스트 마이닝 함수
문자열 추출

- 첫번째 obs의 Actors 변수에서 1~5번째에 해당하는 문자열 추출
문자열 붙이기



- paste()는 기본적으로 붙이는 문자열 사이에 " "(한칸 빈칸)이 기본 설정이다. 이를 수정하기 위해서는 sep = "" 옵션을 주어야 한다.
문자열 분리

문자열 대체

- gsub()은 데이터 핸들링에서 매우 많이 사용되는 명령어이기에 꼭 기억해야 한다.
텍스트 마이닝
텍스트 마이닝의 절차는 다음과 같다.
- 코퍼스 생성
- TDM 생성
- 문자 처리
- 문자열 변수 생성
Genre 변수(이전 데이터셋)는 영화에 대한 장르를 나타낸다. 하지만 모든 영화가 하나의 장르에만 해당되는 것이 아니라, 여러 장르에 해당되는 것을 알 수 있다.
이를 분석하기 위해 각 영화가 어느 장르에 해당되는지 나타내줄 수 있는 변수를 만들어야 한다. 해당 변수를 만들기 위해 텍스트 마이닝 기법을 적용시켜보자.
- 1단계 : 코퍼스 생성
영어의 경우, 대문자와 소문자가 다른 글자로 인식되기 때문에 바꿔주는 작업이 필요하다.
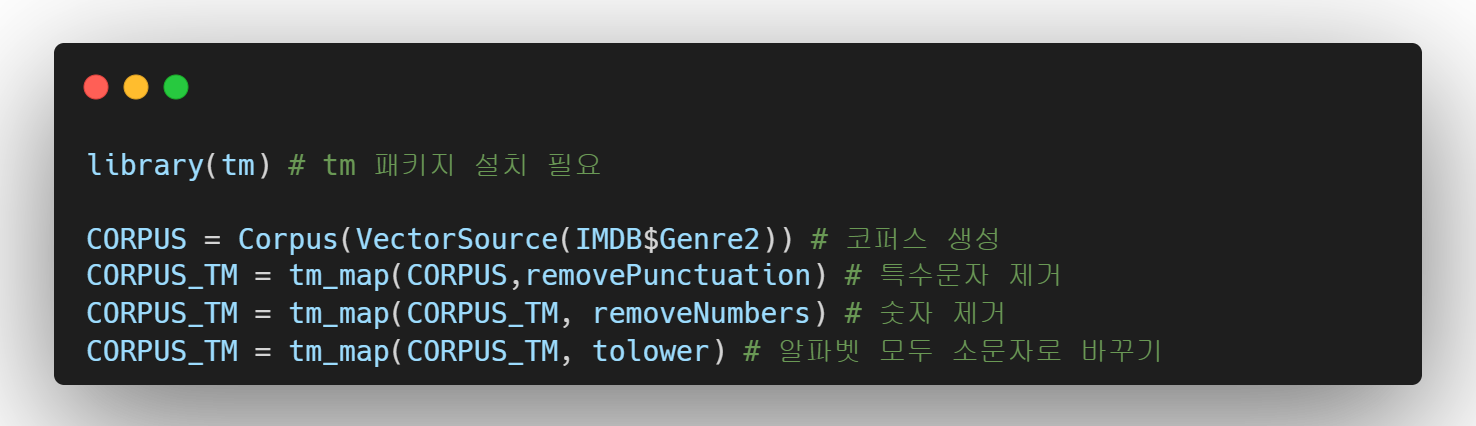
코퍼스는 말뭉치라는 의미로 텍스트 마이닝을 하기 전에 문자열 데이터를 정리하는 과정이라고 생각하면 된다.
- 2단계 : 문서 행렬 생성
문서 행렬을 만드는 이유는 다음과 같다.
- 특정 단어를 변수로 만들어, 분석에 사용하려는 목적
- 특정 단어가 포함되어 있는 데이터만 따로 추출하거나 특정 단어가 많이 등장하였을 때, 이것이 다른 무언가와 상관성이 있는지 분석하기 위한 목적
즉, 문자열 데이터를 가지고 통계적인 분석을 하기 위한 준비과정이라고 생각하면 된다.
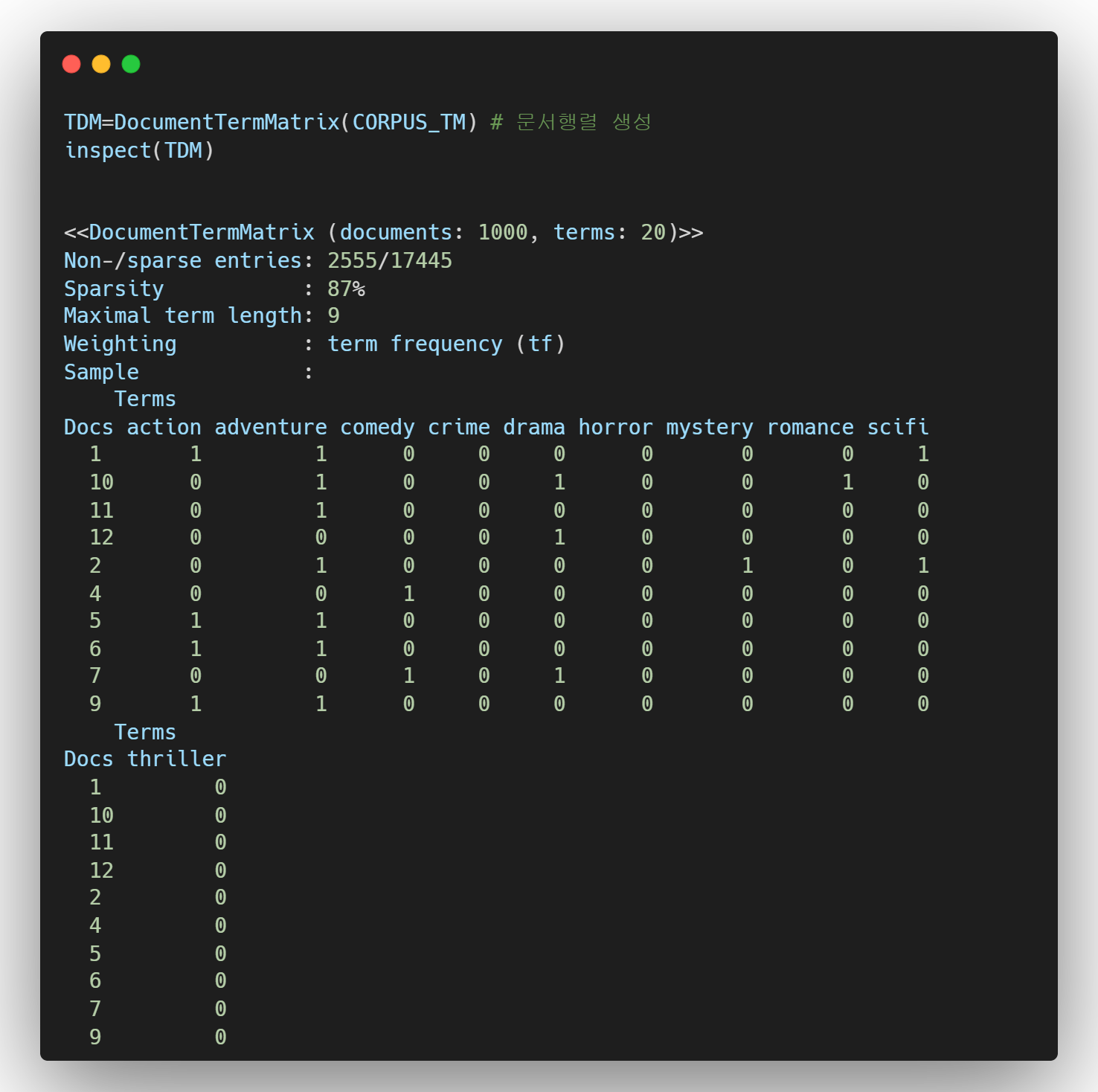
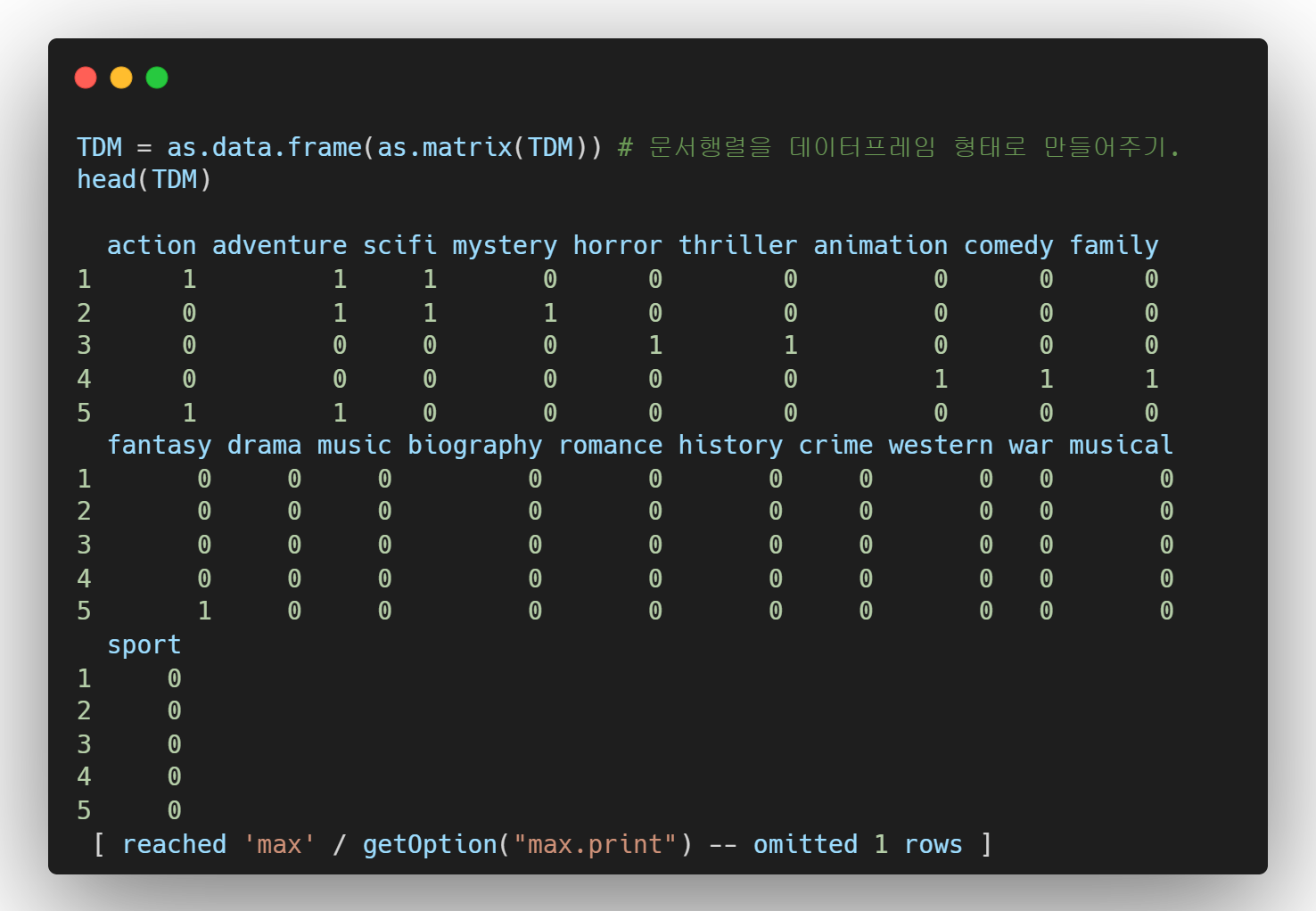
- 3단계 : 기존 데이터와 결합하기

기존에 있는 데이터와 장르 변수들로 구성된 데이터를 합쳐야 한다. 합쳐야 할 두 데이터가 같은 행을 가지고 순서도 같다면 cbind 명령어를 쓰면 되고, 만약 반대로 합쳐야 할 두 데이터가 같은 열을 가지고 순서도 같은데 행을 합쳐야 한다면 rbind를 쓰면 된다.
데이터 결합 명령어
- cbind : 행이 동일하고, 순서도 같을 때 옆으로 합치기
- rbind : 열이 동일하고, 순서도 같을 때 아래로 합치기
- merge : 열과 행이 다른 두 데이터 셋을 하나의 기준을 잡고 합치고자 할 때 사용
Genre 변수를 통해 간단하게 다루어 봤다면 이번에는 Description 변수를 통해 다루어보자. Description 변수는 Genre 변수와 비교했을 때 다음의 차이점이 존재한다.
- 단어의 중복 등장
- 조사, 동사, 명사 등장
- 1단계 : stopwords를 이용한 단어 제거
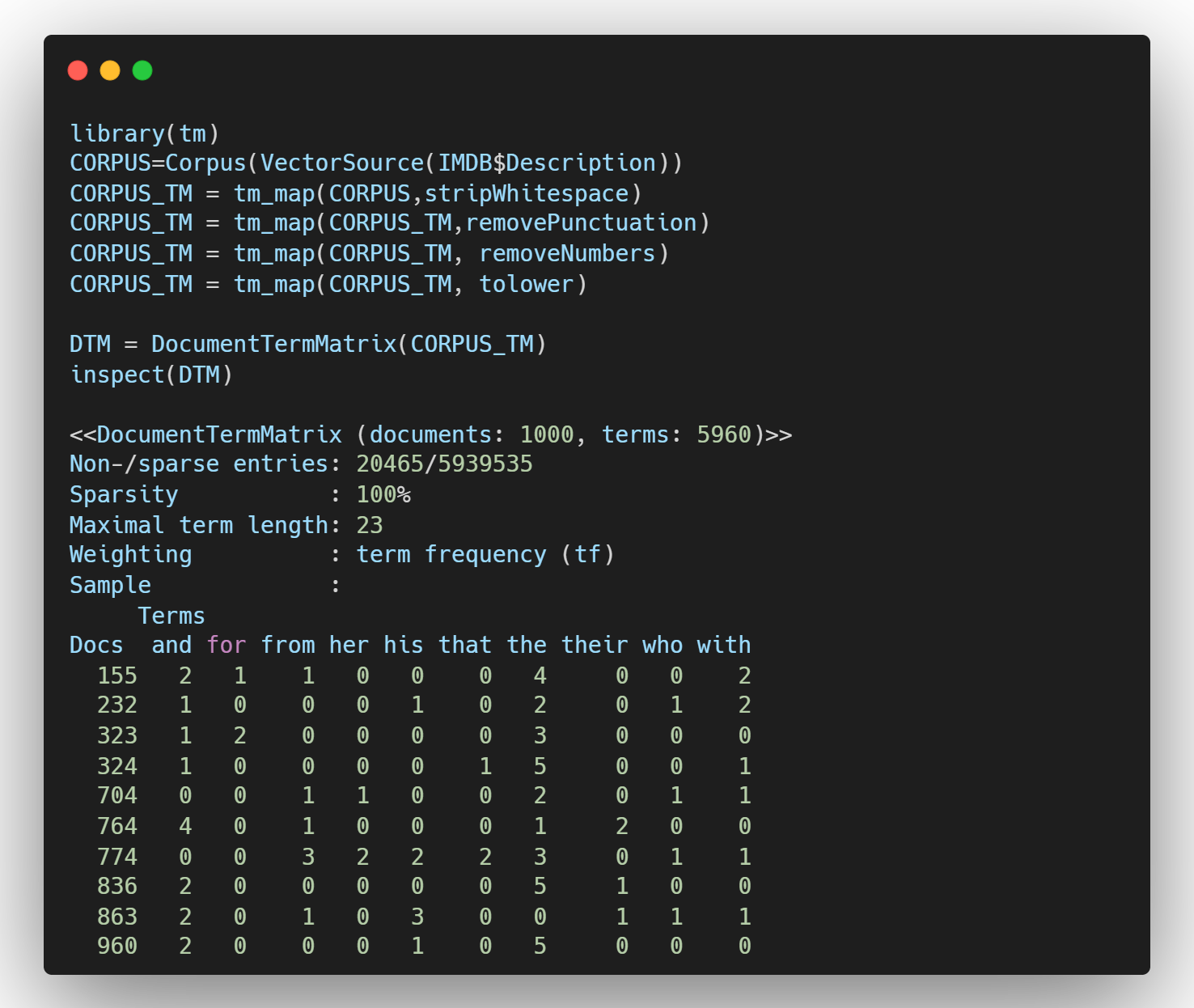
and for from with 이런 단어들은 자주 쓰이지만, 실제로 의미를 전달하는 단어는 아니다. 그러므로 텍스트마이닝 시에 이런 단어들을 제거해주는 것이 더 원활한 분석을 진행할 수 있다.

sropwords 기능을 사용하면 and, his 같은 단어들을 모두 삭제할 수 있다. 더 나아가 추가로 삭제하고 싶은 단어는 c() 명령어 안에 넣어주면 삭제 시킬 수 있다. 여기서는 my, custon, words를 삭제하고 있다.
- 2단계 : 중복등장 단어 처리 결정
문장을 분해한 경우, 중복 단어처리를 어떻게 하느냐도 결정해야될 사항이다.
- 특정 단어가 문장에 포함되어 있냐 없냐로 표시 -> bool값으로 코딩
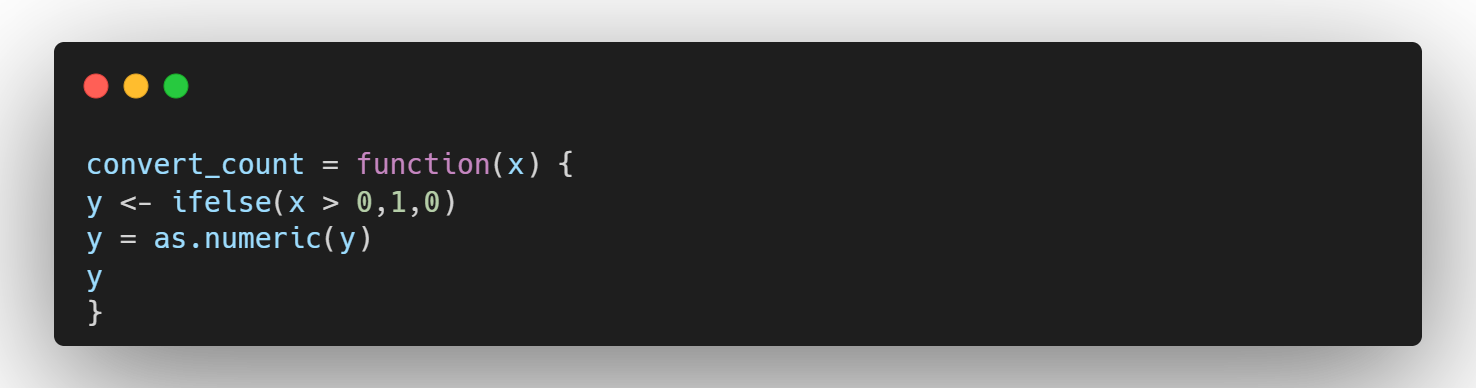
- 특정 단어가 문장에서 몇번 등장했나를 표시 -> 등장 빈도로 코딩
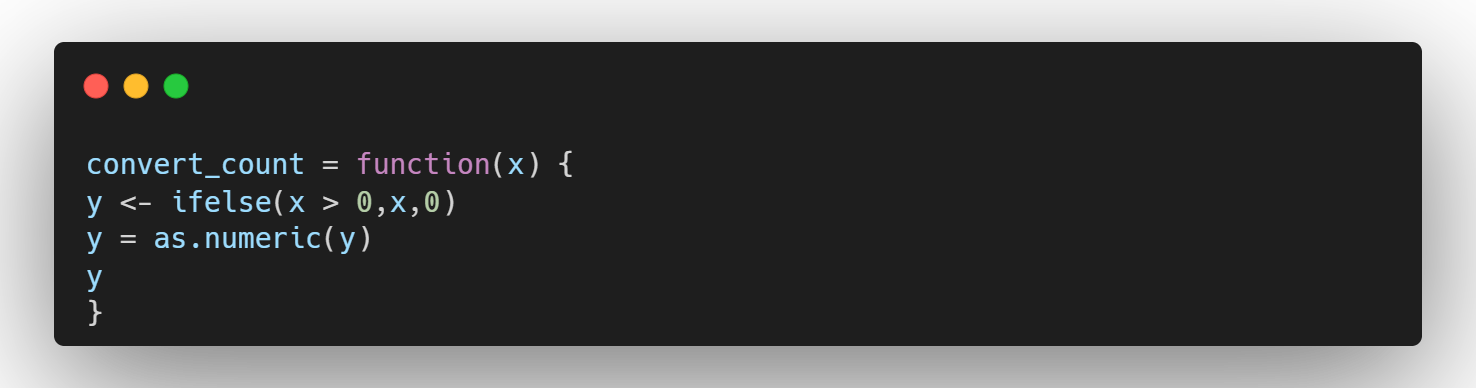
- 사용자 함수 적용
매트릭스 형태인 TDM에 convert_count를 하나씩 적용하여 값을 배출

- 3단계 : 문자열 데이터 시각화
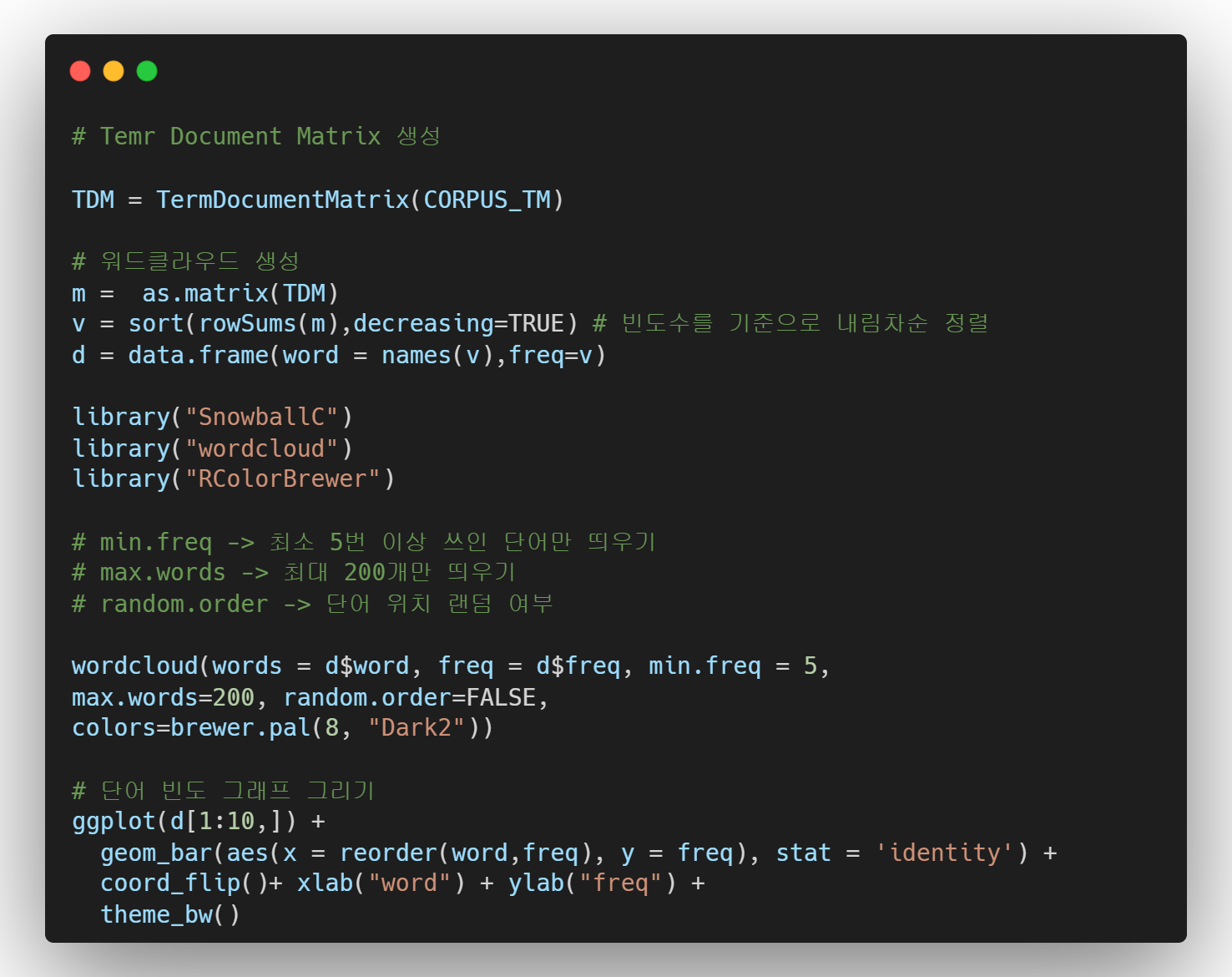

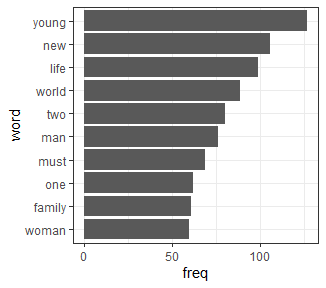
텍스트 마이닝은 사실 통계적인 이용보다는 알고리즘에 기반한 cs에 가깝다. 또한 텍스트를 제대로 분석하기 위해서는 형태소 분석을 기반으로 여러가지 알고리즘을 적용시켜야 그나마 깔끔하게 정리되는 경우가 많다.